引言:为什么提示词工程是开发者的必备技能
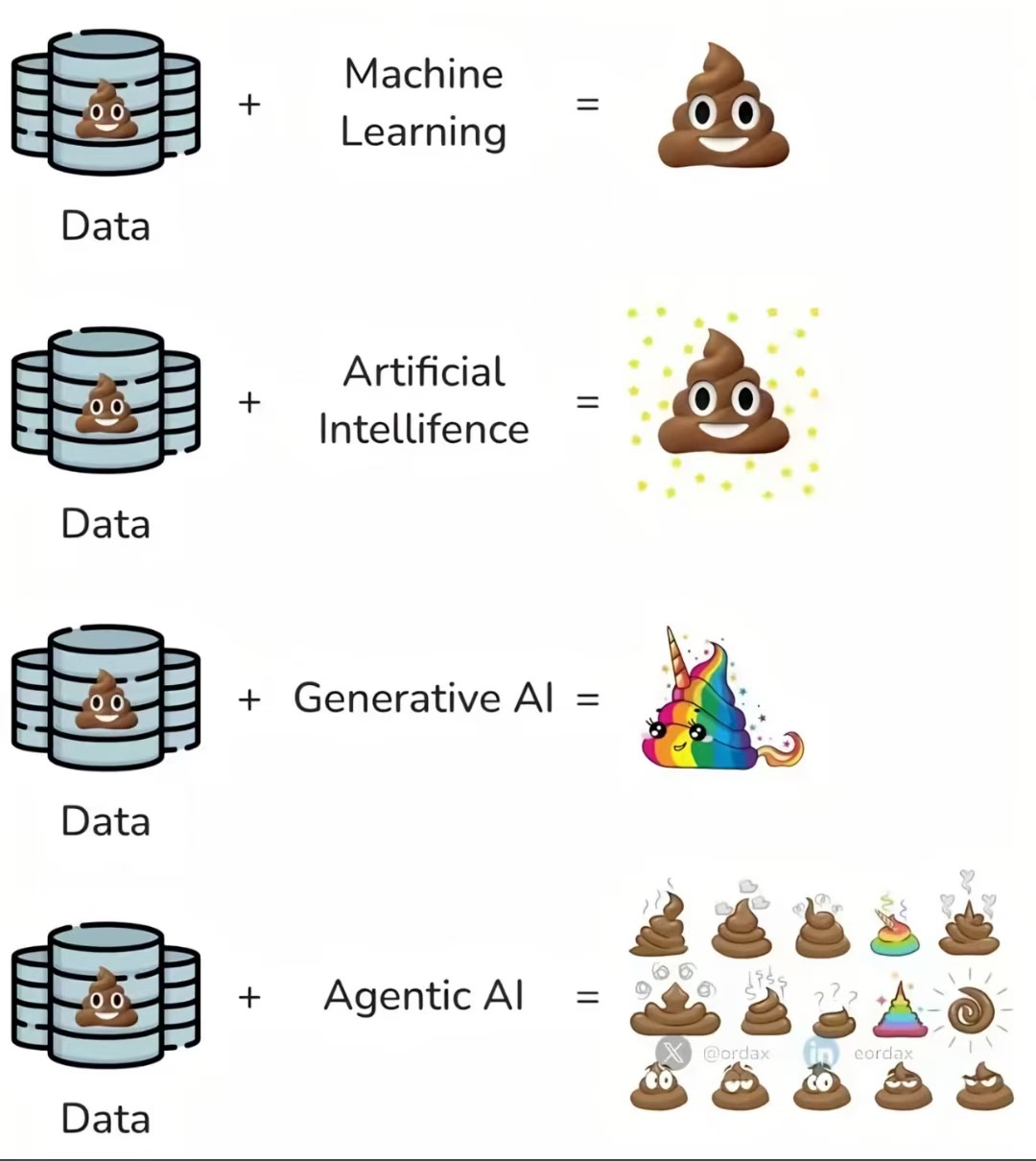
下面这张来自网络的经典图片,不仅仅是诠释了机器学习、人工智能、生成式人工智能和智能体AI之间的区别,最重要的一点是它解释了提示词工程为什么重要。一句话,当你向AI输入垃圾信息时,它也只会为你输出垃圾信息。
在我与众多开发者交流的过程中,我发现了一个有趣的现象:同样使用ChatGPT、Claude或GitHub Copilot,有些开发者能够大幅提升编程效率,而另一些却频繁抱怨”AI生成的代码毫无用处”。这种差异的根本原因不在于AI工具本身,而在于如何与AI对话。
随着AI编程助手的普及,开发者们越来越依赖这些工具来加速日常工作流程。这些工具可以自动补全函数、建议bug修复,甚至生成完整的模块或MVP。然而,正如许多开发者所认识到的,AI输出的质量在很大程度上取决于你提供的提示词质量。
提示词工程不仅仅是一种技能,更是一种思维方式的转变。 它要求我们从”我知道答案,只是想要AI帮我写代码”转向”我要教会AI理解我的问题,然后共同找到最佳解决方案”。
有效代码提示的基础原则
提示词AI编程工具有点像与一个非常字面化、有时很有知识的协作者交流。基于我长期的实践,我总结了以下核心原则:
1. 提供丰富的上下文:让AI成为你的项目内部人员
深度分析: AI模型虽然训练了海量代码,但它对你的具体项目一无所知。这就像新入职的高级工程师——虽然技术能力很强,但需要了解项目背景才能提供有价值的建议。
我的实践技巧:
# 上下文信息模板## 技术栈- 语言:[具体版本]- 框架:[具体版本和配置]- 主要依赖:[关键库]## 项目背景- 项目类型:[Web应用/移动应用/桌面应用等]- 用户规模:[影响架构决策]- 性能要求:[响应时间/并发数等]## 当前问题- 预期行为:[详细描述]- 实际行为:[具体现象]- 错误信息:[完整的错误堆栈]- 复现步骤:[一步步操作]
实例对比:
❌ 差的提示:我的代码不工作✅ 优秀的提示:我正在开发一个Next.js 14电商项目,使用TypeScript和Prisma ORM。在用户下单流程中,有一个库存检查函数总是返回false,导致无法完成订单。技术细节:- Next.js 14 with App Router- PostgreSQL 15 + Prisma 5.x- 预期:当商品库存>0时返回true- 实际:始终返回false- 错误:无明显错误,但逻辑判断异常相关代码:[贴出具体代码]测试数据:商品ID 123,当前库存为5请帮我分析为什么会出现这个问题。
2. 明确目标导向:不要让AI猜测你的意图
我的发现: 在提示词工程中,最大的误区是认为AI能够”读懂你的心思”。实际上,AI需要明确的指令,就像你给初级开发者分配任务一样。
目标明确性的层次:
Level 1 - 基础明确:
"修复这个bug" → "分析这个TypeError并提供修复方案"
Level 2 - 行为明确:
"优化这个函数" → "将这个O(n²)复杂度的函数优化到O(n log n)"
Level 3 - 约束明确:
"重构这个组件" → "将这个类组件重构为函数组件,使用Hooks管理状态,保持现有的prop接口不变,并添加TypeScript类型定义"
我的提示公式:
[动作] + [对象] + [目标] + [约束] + [期望输出格式]示例:重构 + 这个React组件 + 提高性能和可读性 + 不改变外部API + 提供前后对比和解释
3. 分解复杂任务:化整为零的艺术
核心洞察: 人类程序员也不会一次性解决所有复杂问题,AI也不应该被期望这样做。分解任务不仅能获得更好的结果,还能在每一步进行验证和调整。
我的分解策略:
垂直分解(按功能层次):
完整功能 → 数据层 → 业务逻辑层 → 表现层 → 测试层
水平分解(按开发阶段):
需求分析 → 架构设计 → 核心实现 → 错误处理 → 性能优化 → 测试完善
实际案例:构建用户认证系统
# 第一步:架构设计"设计一个JWT based的用户认证系统架构,包括:- 主要模块和职责- 数据流向- 安全考量点- 技术栈:Node.js + Express + MongoDB"# 第二步:核心实现"基于上述架构,实现用户注册功能:- 输入验证(邮箱格式、密码强度)- 密码加密存储- 避免重复注册- 返回标准化响应"# 第三步:完善功能"为上述注册功能添加:- 邮箱验证机制- 注册失败的详细错误提示- 日志记录- 单元测试用例"
4. 示例驱动的提示设计
重要发现: 在我的实践中,包含具体示例的提示比纯文字描述的效果要好70%以上。这是因为示例能够消除歧义,让AI理解你的确切期望。
示例类型分类:
输入输出示例:
实现一个函数parseUserInput,处理用户搜索输入:输入示例:- "JavaScript tutorial" → {type: "search", query: "JavaScript tutorial", filters: []}- "category:frontend js" → {type: "search", query: "js", filters: [{type: "category", value: "frontend"}]}- "/help" → {type: "command", command: "help"}请实现这个函数并处理边界情况。
行为示例:
创建一个React Hook useDebounce,行为如下:const debouncedValue = useDebounce(searchTerm, 300);// 当searchTerm变化时,debouncedValue在300ms后更新// 如果300ms内searchTerm再次变化,重新计时使用场景:搜索框实时查询,避免频繁API调用。
错误处理示例:
为API调用添加错误处理,需要区分:- 网络错误:显示"网络连接失败,请重试"- 401错误:跳转到登录页- 403错误:显示权限不足提示- 429错误:显示"请求过于频繁,请稍后再试"- 500错误:显示通用错误信息并记录到监控系统
5. 角色扮演的高级应用
深度思考: 角色扮演不仅仅是给AI戴个”帽子”,而是激活其在特定领域的知识模式。不同的角色会带来不同的思考角度和解决方案。
我的角色库:
代码审查者角色:
"作为资深代码审查者,审查以下代码并提供详细反馈:审查维度:1. 代码质量(可读性、维护性)2. 性能问题(时间复杂度、空间复杂度)3. 安全隐患(输入验证、SQL注入等)4. 最佳实践(设计模式、命名规范)5. 测试覆盖(边界条件、异常处理)请按严重程度排序问题,并提供具体的修改建议。"
架构师角色:
"作为系统架构师,为以下需求设计技术方案:考虑因素:- 可扩展性(用户增长10倍如何应对)- 可维护性(团队规模、技术债务)- 性能要求(响应时间、吞吐量)- 成本控制(开发成本、运维成本)- 技术风险(技术选型、依赖管理)请提供:架构图、技术选型理由、风险评估、实施路径。"
性能专家角色:
"作为前端性能优化专家,分析这个React应用的性能问题:关注点:- 首屏加载时间(FCP、LCP)- 交互响应性(FID、CLS)- 资源加载优化(代码分割、缓存策略)- 运行时性能(内存泄漏、重渲染)请提供具体的优化方案和预期效果。"
6. 对话式迭代优化
核心理念: 把与AI的交互看作结对编程,而不是一次性的代码生成。最好的解决方案往往来自于多轮的讨论和改进。
我的迭代模式:
探索 → 实现 → 评估 → 优化 → 验证
# Round 1: 探索阶段"我需要实现一个缓存系统,你觉得有哪些方案可以考虑?"# Round 2: 方案对比"请详细比较LRU、LFU和TTL缓存策略的优缺点,以及适用场景。"# Round 3: 具体实现"基于我们的讨论,使用LRU策略实现一个内存缓存类,支持设置最大容量。"# Round 4: 功能增强"为缓存类添加统计功能:命中率、平均访问时间、内存使用量。"# Round 5: 错误处理"添加完善的错误处理和边界条件检查。"# Round 6: 性能优化"分析一下这个实现的性能特点,有什么可以优化的地方?"
调试代码的高级提示技巧
调试是开发者日常工作中最频繁的任务之一,也是AI助手能够发挥巨大价值的领域。基于我的实践经验,我开发了一套系统化的调试提示方法。
1. 症状导向的问题描述
我的发现: 最有效的调试提示不是简单地说”代码有bug”,而是像医生诊断一样,详细描述”症状”。
症状描述模板:
## 问题症状- **预期行为:** [具体描述正常情况下应该发生什么]- **实际行为:** [详细描述当前发生的情况]- **触发条件:** [什么情况下会出现问题]- **错误频率:** [总是发生/偶发/特定条件下]## 环境信息- **运行环境:** [浏览器版本/Node.js版本/操作系统]- **数据状态:** [相关变量的值]- **执行路径:** [代码执行到哪一步出问题]## 已尝试的方法- [列出你已经尝试过的解决方案]- [排除了哪些可能的原因]
实际案例分析:
❌ 低效的调试提示:
"我的React组件不渲染,帮我看看哪里错了。function UserProfile() {// ... 一大段代码}
✅ 高效的调试提示:
"React组件UserProfile遇到渲染问题,具体症状如下:## 问题描述- **预期:** 用户登录后显示用户头像、姓名和邮箱- **实际:** 组件渲染为空白,控制台无错误- **触发:** 用户ID存在且API返回正常数据时- **环境:** Chrome 120, React 18.2.0## 调试信息- API响应正常:{id: 123, name: "张三", avatar: "..."}- 组件确实被挂载(通过React DevTools确认)- 父组件传递的props正确## 相关代码function UserProfile({ userId }) {const [user, setUser] = useState(null);useEffect(() => {fetchUser(userId).then(setUser);}, [userId]);console.log('User data:', user); // 打印正常return (<div>{user && (<div><img src={user.avatar} /><h3>{user.name}</h3><p>{user.email}</p></div>)}</div>);}## 困惑点数据获取正常,条件判断看起来也对,但就是不显示内容。可能是什么原因?
2. 对话式逐行解释调试
逐步调试提示:
"我来逐步解释这个函数的执行过程,请你指出可能的问题:这个函数的目的是计算购物车总价:function calculateTotal(items) {let total = 0;for (let i = 0; i <= items.length; i++) { // 我遍历所有商品total += items[i].price * items[i].quantity; // 累加每个商品的价格×数量}return total;}我的推理:1. 初始化total为0 ✓2. 遍历items数组 ✓3. 每次循环计算price×quantity并累加 ✓4. 返回总价 ✓但是运行时抛出 'Cannot read property price of undefined'。请分析我的推理哪里有问题?"
AI通常能准确指出: “你的循环条件使用了 i <= items.length,这会导致最后一次迭代访问 items[items.length],这个索引是不存在的…”
3. 分层调试策略
方法论: 复杂的bug往往涉及多个层次,我开发了一套分层调试的提示策略。
分层调试模板:
"这个问题可能涉及多个层次,请帮我逐层分析:## 第一层:语法和基础逻辑[贴出核心代码段]是否存在语法错误、类型错误、基础逻辑问题?## 第二层:数据流和状态管理输入数据:[实际的输入值]中间状态:[关键变量的值]输出结果:[实际输出]数据在处理过程中是否发生了意外变化?## 第三层:异步和时序问题是否涉及异步操作?是否存在竞态条件?事件触发的时序是否正确?## 第四层:环境和依赖运行环境是否一致?第三方库版本是否兼容?是否存在环境特定的行为差异?请按层次分析,找出最可能的问题源头。"
4. 性能调试技巧
性能问题的特殊性: 性能bug往往不会抛出明显错误,需要特殊的调试策略。
性能调试提示模板:
"遇到性能问题,需要系统性分析:## 性能现象- **具体指标:** [加载时间/响应时间/内存使用等具体数字]- **性能基线:** [期望的性能标准]- **性能趋势:** [是否随时间/数据量恶化]## 性能瓶颈分析请帮我分析以下代码的性能特征:[贴出代码]关注点:1. 算法复杂度分析2. 内存使用模式3. 频繁操作识别4. 潜在的性能陷阱## 优化方向基于分析结果,建议:- 短期优化方案(快速见效)- 长期重构方案(根本解决)- 监控指标设置"
5. 角色扮演调试技巧
## AI扮演不同的"调试伙伴"### 新手程序员角色"我是新手,请用最简单的话解释,有什么我不懂的地方我会问。"(这会让你用最基础的方式思考问题)### 资深架构师角色"我会从系统设计角度审视你的代码,指出潜在的架构问题。"(帮你发现更深层次的设计问题)### 严格的代码审查者角色"我会用最严格的标准审查你的代码,不放过任何细节。"(帮你发现边界情况和潜在bug)### 性能优化专家角色"我专注于性能,会质疑每一个可能的性能瓶颈。"(帮你优化算法和提升效率)
实用的AI辅助调试提示模板
基础调试模板:
"我遇到一个bug,想用逐行解释的方法来分析。请你扮演一个智能调试助手:## 当前问题[描述问题现象]## 相关代码[贴出代码]## 我的解释过程我现在开始逐行解释代码逻辑,请你:1. 在每个关键步骤提出验证性问题2. 指出可能的逻辑漏洞3. 建议需要考虑的边界情况4. 提醒我可能忽略的细节让我们开始逐行分析..."
高级调试模板:
"我需要一个AI调试伙伴来帮我深度分析问题:## 调试目标不仅要找到当前的bug,还要:- 发现潜在的设计问题- 提升代码的健壮性- 优化性能和可维护性- 确保最佳实践的应用## 调试角色请你在对话中灵活切换以下角色:- 🔍 细心的代码检查员(发现逻辑错误)- 🏗️ 架构评审员(审视设计合理性)- ⚡ 性能分析师(关注效率问题)- 🛡️ 安全审计员(检查安全隐患)- 📚 最佳实践导师(推荐改进方案)## 互动方式- 我解释一段逻辑,你立即反馈和提问- 你可以主动提出需要我澄清的地方- 在发现问题时,请引导我自己找到答案- 提供多个解决方案供我选择准备好了吗?我们开始深度调试之旅!"
重构和优化的深度实践
重构是提升代码质量的重要手段,也是AI助手能够提供巨大价值的领域。基于我的经验,成功的重构提示需要平衡多个维度的考量。
1. 多维度重构目标定义
核心洞察: “重构”是一个模糊的概念,需要将其具体化为可操作的目标。我总结了六个主要维度:
重构维度框架:
## 1. 可读性维度- 变量命名是否清晰表意- 函数职责是否单一明确- 代码结构是否符合逻辑- 注释是否必要且准确## 2. 性能维度- 算法复杂度是否最优- 内存使用是否高效- 网络请求是否合理- 缓存策略是否得当## 3. 维护性维度- 代码耦合度是否过高- 是否便于测试- 是否便于扩展- 配置是否灵活## 4. 安全性维度- 输入验证是否充分- 权限控制是否严格- 敏感信息是否保护- 错误信息是否泄露## 5. 现代化维度- 是否使用最新最佳实践- 是否符合团队规范- 是否利用新特性优化- 是否消除过时用法## 6. 业务适配维度- 是否满足当前业务需求- 是否为未来需求预留空间- 是否符合领域模型- 是否便于业务理解
多维度重构提示示例:
"请对以下代码进行多维度重构:## 当前代码[贴出代码]## 重构目标(按优先级)1. **性能优化**:当前函数在处理大数据集时性能不佳2. **可读性提升**:新团队成员反馈代码难以理解3. **维护性改进**:需要支持更多的数据源类型4. **现代化改造**:升级到ES2023语法特性## 约束条件- 保持现有API接口不变- 向后兼容旧数据格式- 单元测试必须通过- 代码行数控制在原来的80%以内请提供重构方案和详细说明。"
2. 渐进式重构策略
方法论: 大型重构往往风险很高,我推荐渐进式重构,每次专注于一个小目标。
渐进式重构流程:
第一轮:安全性重构(不改变行为)↓第二轮:可读性重构(提升理解度)↓第三轮:结构性重构(改进架构)↓第四轮:性能性重构(优化效率)↓第五轮:现代化重构(应用新技术)
实际案例:重构一个数据处理函数
第一轮提示:安全性重构
"首先进行安全性重构,重点关注:原始代码:function processUserData(userData) {let result = [];for (let i = 0; i < userData.length; i++) {if (userData[i].age > 18) {result.push({name: userData[i].name,email: userData[i].email,score: userData[i].score * 1.2});}}return result;}重构要求:1. 添加输入参数验证2. 处理空值和异常情况3. 确保不会抛出未捕获异常4. 保持原有功能完全不变只做安全性改进,不改变其他方面。"
第二轮提示:可读性重构
"基于第一轮的安全版本,现在进行可读性重构:目标:1. 改进变量和函数命名2. 提取魔法数字和字符串3. 添加适当的注释4. 简化复杂表达式要求:- 让初级开发者也能快速理解代码意图- 每个变量名都应该明确表达其用途- 业务逻辑应该一目了然"
第三轮提示:结构性重构
"继续进行结构性重构:目标:1. 将单一函数拆分为多个职责明确的小函数2. 应用适当的设计模式3. 提高代码的可测试性4. 减少耦合度考虑:- 过滤逻辑可以独立- 数据转换逻辑可以独立- 评分计算逻辑可以配置化"
3. 重构效果量化评估
创新实践: 我发现让AI帮助量化重构效果,能够更好地验证重构的价值。
重构评估提示:
"请对重构前后的代码进行量化比较:## 重构前代码[原始代码]## 重构后代码[重构后代码]## 评估维度请从以下维度给出具体的改进指标:### 复杂度指标- 圈复杂度变化- 函数行数变化- 嵌套层级变化- 参数数量变化### 可维护性指标- 耦合度评分(1-10)- 内聚性评分(1-10)- 可测试性评分(1-10)- 可扩展性评分(1-10)### 性能指标- 时间复杂度比较- 空间复杂度比较- 预期性能提升百分比### 代码质量指标- 代码重复度- 命名质量评分- 注释覆盖度- 遵循最佳实践程度请为每个指标提供具体的数值或评级,并解释改进的原因。"
实现新功能的系统化方法
实现新功能是开发者最富有创造性的工作,也是AI助手能够提供最大价值的场景。我开发了一套系统化的方法来最大化AI的帮助效果。
1. 需求驱动的功能设计
核心理念: 在编写任何代码之前,先与AI共同分析和细化需求,确保对问题的理解是准确和完整的。
需求分析模板:
## 功能需求描述"我需要实现一个[功能名称],具体需求如下:### 核心用例**主要用户:** [目标用户群体]**使用场景:** [在什么情况下使用]**核心价值:** [解决什么问题]### 功能规格**输入:** [用户提供什么]**处理:** [系统做什么操作]**输出:** [用户得到什么结果]**约束:** [性能、安全、兼容性要求]### 交互流程1. [用户操作步骤1]2. [系统响应步骤1]3. [用户操作步骤2]4. ...请帮我分析这个需求,指出可能的模糊点、边界情况和技术难点。"
需求澄清对话示例:
人类:"我想做一个搜索功能"AI:"搜索功能的实现方式很多,为了给出最适合的方案,我需要了解:1. 搜索的数据源是什么?(数据库、文件、API等)2. 数据量大概有多少?(影响搜索策略选择)3. 搜索类型需要支持哪些?(精确匹配、模糊匹配、全文检索等)4. 性能要求如何?(搜索响应时间期望)5. 用户体验期望?(实时搜索、搜索建议、历史记录等)"人类:"数据源是PostgreSQL数据库,大概10万条商品记录,需要支持商品名称和描述的模糊搜索,响应时间希望在200ms以内,需要搜索建议功能。"AI:"明确了!基于你的需求,我建议使用以下技术方案:1. 数据库层面使用PostgreSQL的全文搜索功能2. 应用层实现搜索建议的防抖机制3. 前端使用虚拟滚动处理大量结果接下来我们分步骤实现..."
2. 架构优先的设计方法
深度思考: 直接让AI写代码往往会得到”能用但不优雅”的解决方案。更好的方式是先讨论架构设计,再逐步实现。
架构设计提示模板:
"在开始编码之前,请帮我设计[功能名称]的技术架构:## 技术背景- **技术栈:** [现有技术栈]- **系统规模:** [用户量、数据量、并发量]- **集成需求:** [需要集成的外部系统]## 架构设计要求1. **可扩展性:** 如何应对[具体的扩展场景]2. **可维护性:** 如何降低后续开发和维护成本3. **可测试性:** 如何确保充分的测试覆盖4. **性能要求:** [具体的性能指标]## 设计产出请提供:- 模块划分和职责定义- 数据流图- 主要接口设计- 错误处理策略- 监控和日志方案然后我们再基于这个架构进行具体实现。"
架构讨论的实际案例:
需求:"实现一个实时聊天功能"架构讨论:AI:"实时聊天涉及多个架构决策:## 通信协议选择1. **WebSocket:** 适合高频双向通信,延迟低2. **Server-Sent Events:** 适合服务器推送为主的场景3. **Long Polling:** 兼容性好,但性能稍差消息存储策略1. **关系数据库:** 适合复杂查询和事务处理2. **NoSQL数据库:** 适合高并发和水平扩展3. **内存数据库:** 适合临时消息和会话状态## 扩展性考虑1. **单机版:** 适合小规模团队(<1000用户)2. **集群版:** 需要考虑消息路由和状态同步3. **微服务版:** 适合大规模系统,但复杂度高基于具体需求,你的推荐方案是..."
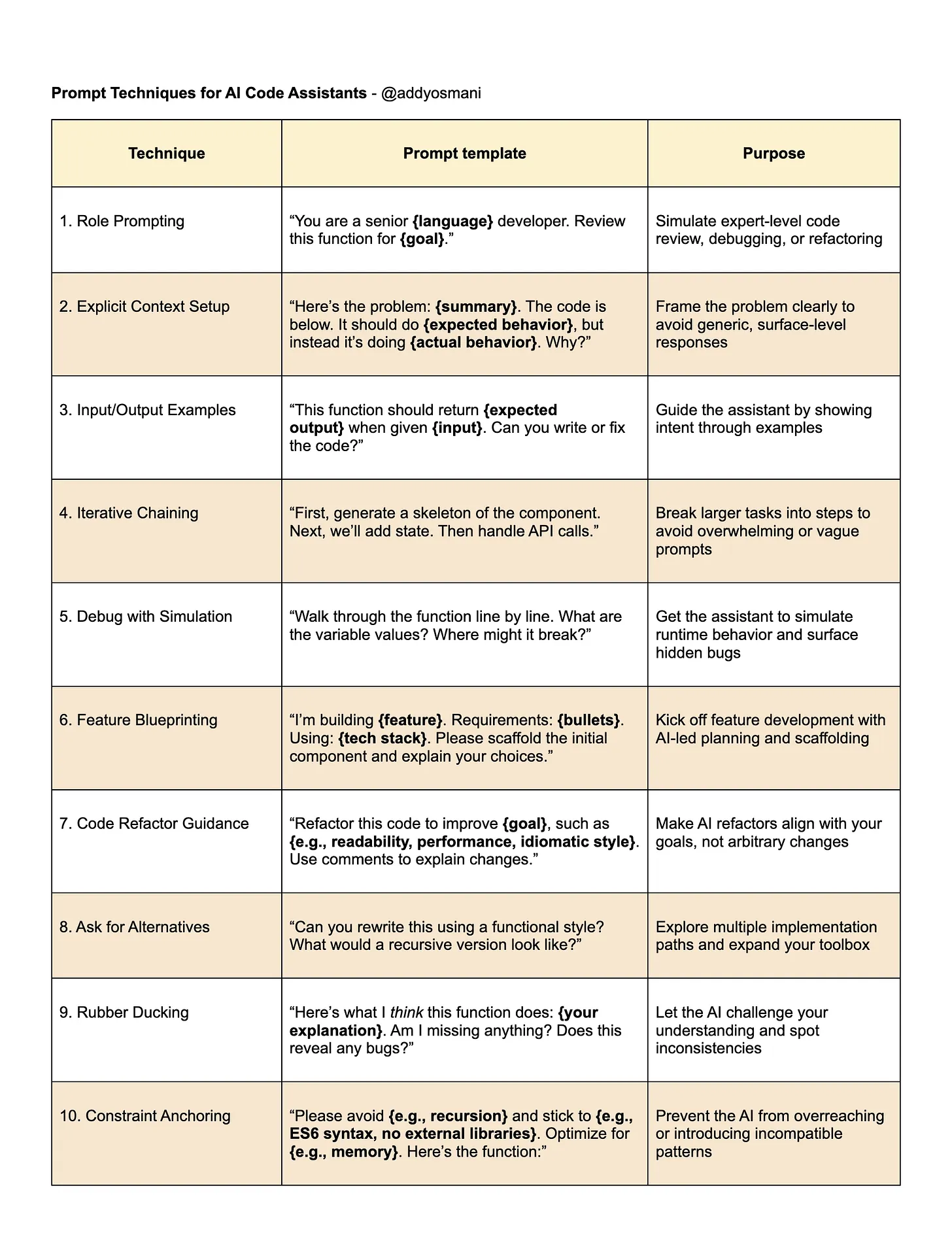
给 AI 代码助手的提示词技巧 - @addyosmani